Dernière révision le 2026/05/29 a 10:22

“Selfie” créé via Midjourney et poster sur Reddit comme étant une image générée par IA.
Ce selfie d’un manifestant pris sur la place Tiananmen pendant les émeutes de 1989 est un faux, généré par une IA.
Le problème se complexifie car il s’agit de l’une des premières images affichées par Google lorsqu’on recherche « Tiananmen Square », se mêlant ainsi aux véritables photos de l’événement. Aucune indication ne signale qu’il s’agit d’une image synthétique. Et ce n’est pas un cas isolé.
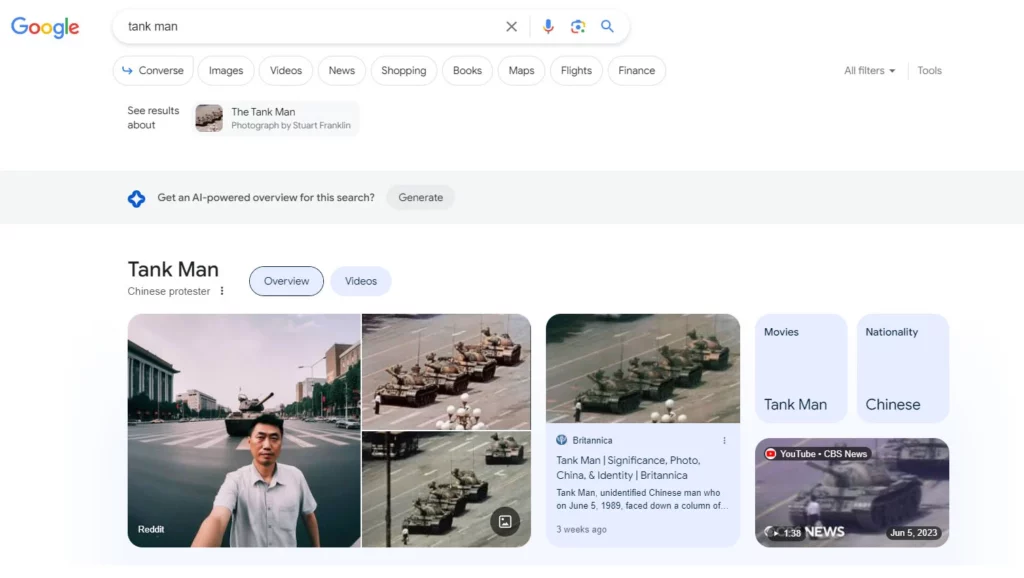
Capture d’écran du résultat d’une recherche sur Tiananmen, (avant que Google rectifie après publication d’articles concernant ce problème)
De plus en plus, les photographies créées par une IA générative se retrouvent parmi les premiers résultats des moteurs de recherche sans aucune marque distinctive. Avec plus de 15 milliards d’images synthétiques créées au cours de la dernière année—un nombre surpassant celui des images créées dans toute l’histoire de la photographie—la situation n’est guère surprenante.
C’est néanmoins extrêmement problématique pour notre société et nos démocraties. Si nous ne pouvons plus distinguer le réel du faux, comment prendre des décisions éclairées ? D’autant plus que les moteurs de recherche sont désormais la principale source d’information pour beaucoup. L’ampleur du problème est donc considérable.
La technologie seule ne peut pas résoudre ce problème. Chaque tentative de création d’algorithmes pour détecter et identifier automatiquement le contenu faux est rapidement surpassée par des méthodes plus sophistiquées de création de faux contenus.
Cependant, il existe une solution : une initiative lancée par Adobe il y a plus de 2 ans, soutenue par des géants comme Microsoft, la BBC, le New York Times, Sony, Nikon, Canon et Publicis. Cette initiative, nommée Content Credentials, propose une norme d’étiquetage permettant d’identifier rapidement la source d’une image, et ainsi de savoir immédiatement si elle est synthétique ou non. Elle contribue également à évaluer sa crédibilité.
Comment ça marche ?
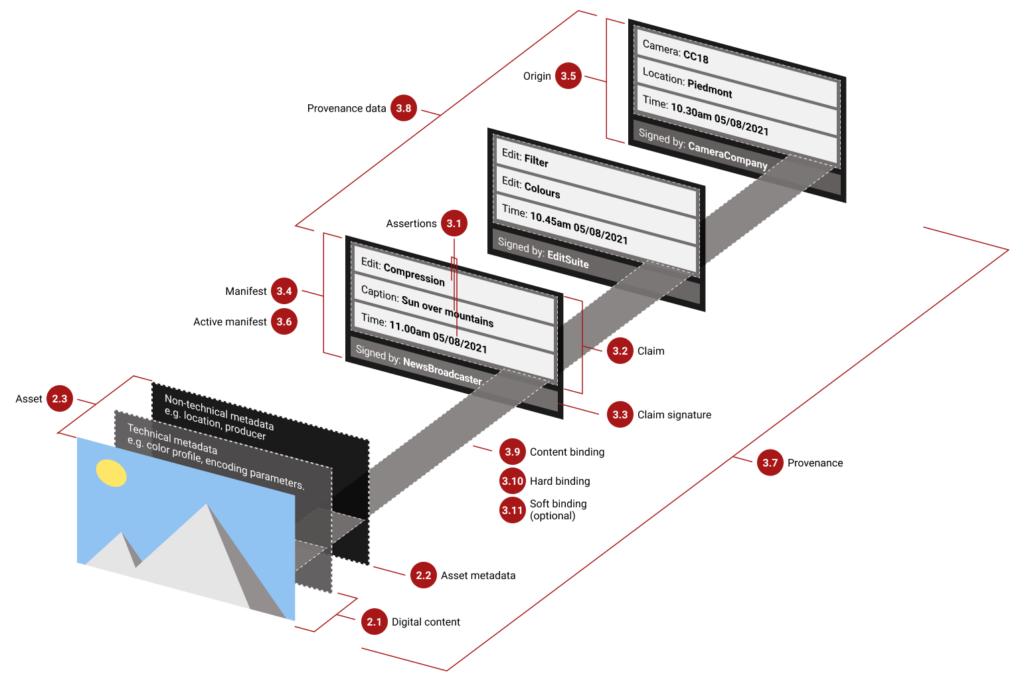
Visualisation du processus du Content Credential
Le créateur d’une image fournit des informations sur qui, où, quand et comment une image a été prise. Ces informations sont inscrites dans un manifeste accompagnant l’image en tant que métadonnées de manière automatisée. Chaque modification, de quelque nature que ce soit, est également ajoutée au manifeste. Une fois l’image publiée, le manifeste peut être vu et consulté, permettant ainsi aux lecteurs de connaître toute l’histoire de l’image. Si l’image a été créée par un générateur d’images ou fortement modifiée par l’IA, cela est clairement indiqué. Cette mesure peut aussi aider à déterminer la crédibilité d’une photographie.
L’idée est qu’en connaissant l’origine d’une image, on peut comprendre l’intention de son créateur. L’initiative Content Credentials ne révélera pas si une image dépeint la vérité, mais elle vous informera sur la fiabilité de ce que vous voyez.
Idéalement, des moteurs de recherche comme Google ou des plateformes de médias sociaux comme Meta pourraient utiliser le Content Credential pour discerner entre les images réelles et synthétiques, ainsi qu’entre le photojournalisme et la propagande, au bénéfice de tous. Cependant, tout le monde n’est pas d’accord.
Pourquoi donc ?
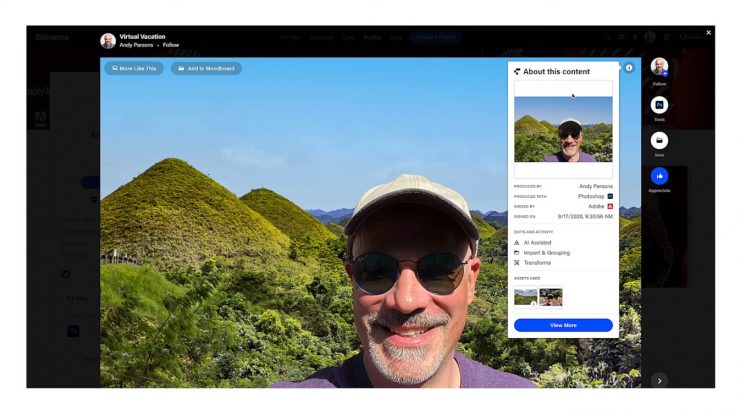
Exempla du Content credential
Deux obstacles majeurs entravent sa mise en œuvre : l’un politique, l’autre commercial.
Sur le front politique, des entreprises comme Google, Facebook et Twitter hésitent. Elles sont conscientes de leur pouvoir décisif quant à l’adoption de cette norme. Pour des plateformes comme Meta, ce ne serait pas bénéfique commercialement car les publications véhiculant de fausses rumeurs—celles qui génèrent le plus de vues et donc de revenus—seraient rapidement démasquées. Quant aux moteurs de recherche, ils préféreraient que chacun utilise leurs systèmes propriétaires pour exercer davantage de contrôle sur Internet et ses utilisateurs.
Du côté commercial, la réticence est principalement financière. La mise en œuvre coûte cher aux agences de presse et aux éditeurs sans promettre de revenus supplémentaires en retour. Personne ne paiera plus pour une image dotée de Content Credentials, du moins pas dans un futur proche.
Certains arguent que les créateurs d’images IA devraient assumer la responsabilité et clairement étiqueter leur production. Des entreprises comme Adobe et Bing ont commencé à le faire en utilisant des Content Credentials, tandis que d’autres, comme Google, utilisent leur propre système.
Un espoir demeure car les fabricants d’appareils photo semblent comprendre qu’ils pourraient jouer un rôle crucial. Ils ont un intérêt à fournir des identifiants confirmant l’authenticité s’ils veulent continuer à vendre leurs appareils. En effet, les Content Credentials permettraient de distinguer clairement les « vraies » images, prises avec leur appareil, des images générées par des algorithmes, et ainsi de justifier leur coût d’achat. Sans cette distinction, pourquoi investir dans un appareil photo coûteux ?
Une autre option, moins élégante, consisterait à légiférer pour imposer une norme commune. Cependant, cela pourrait être perçu comme une intrusion grave dans notre liberté d’information, et la mise en œuvre pourrait être lente.
Tous s’accordent sur le fait qu’il s’agit d’une étape cruciale pour préserver la crédibilité de nos images et, par conséquent, nos informations et nos démocraties. Mais il reste encore beaucoup à faire, surtout avec d’importantes élections prévues l’année prochaine aux États-Unis, au Mexique et en Afrique du Sud. L’urgence est réelle.
Paul Melcher a occupé des postes clés dans des entreprises telles que Stipple, Digital Railroad, PictureGroup, Hachette Filipacchi, Corbis et Gamma. Il a vendu son agence photo, ImageDirect, à Getty Images. Fort de plus de 30 ans d'expérience, il est spécialisé dans l'exploitation de contenu visuel, les innovations technologiques et l'entrepreneuriat au sein d'entreprises visuelles de renommée internationale.
Il a été désigné par American Photo comme l'un des "100 individus les plus influents de la photographie américaine" et a reçu un prix de la Digital Media Licensing Association.